5.1 tidyr::
Las principales funciones son:
pivot_longer pivot_wider separate unite join
Por lo general en la etapa de toma de datos en el campo/lab (y su consiguiente pasaje a planilla electrónica, Excel) nos resulta más cómodo que las planillas de papel tengan un formato wide.
En muchas ocasiones necesitamos (para graficar o modelar) que nuestros datos estén en formato long.
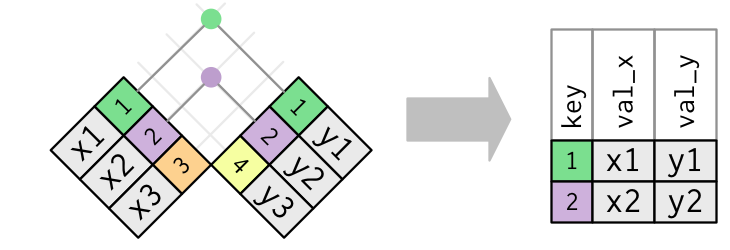
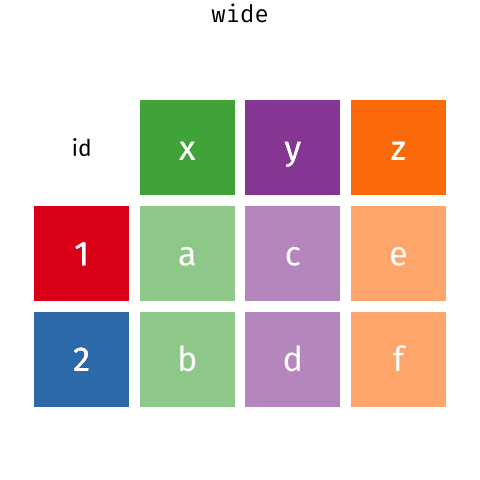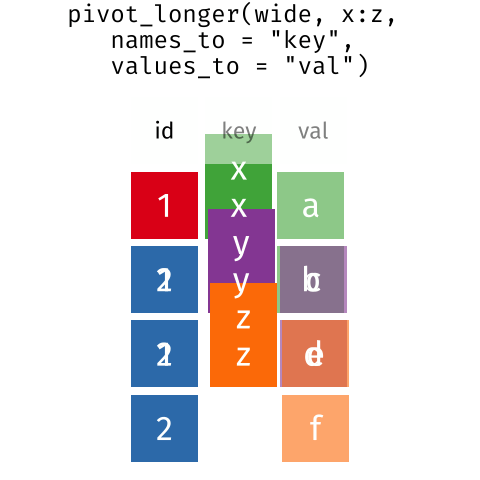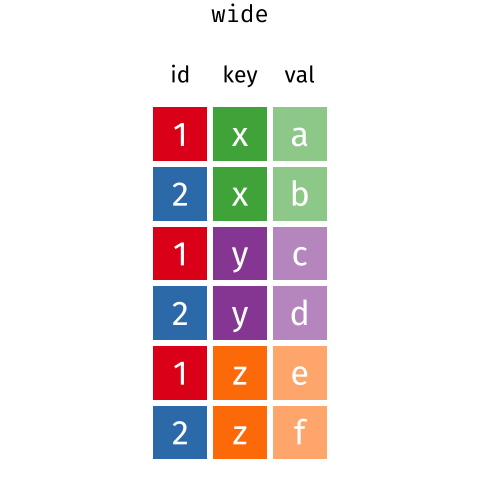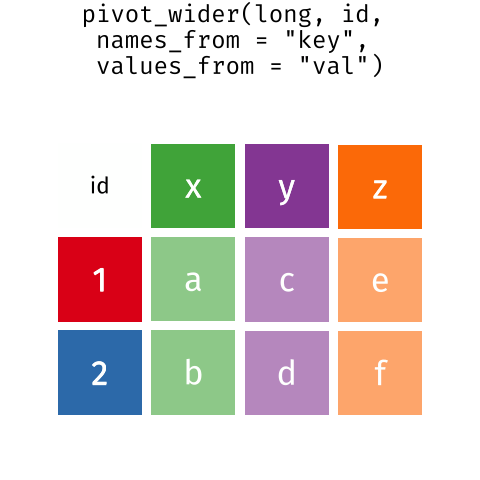
La función pivot_longer apila las columnas que indiquemos, re-arregando los datos de un formato “wide” a “long”:
Datos soja
soja <- readxl::read_excel("data/soja.xls")
soja %>%
pivot_longer(
# cols = c(bk_1, bk_2, bk_3, bk_4),
cols = bk_1:bk_4,
# cols = starts_with("bk"),
names_to = "bk",
values_to = "yield",
names_prefix = "bk_"
) -> soja_longEsto se leería: al dataset soja apilar las columnas de bk_1 a bk_4 de manera tal que los nombres de estas 4 columnas queden contenidos en una columna llamada “bk” (del inglés “block”) y a los valores de rendimiento de las mismas apilarlos en una única columna llamada yield. tidyrse encargrá de repetir los niveles de la variable trttantas veces como sea necesario… al producto resultante lo llamaremos soja_long
Si bien este ejemplo no representaría demasiado trabajo en excel, pensemos en datasets de mayor dimensión como ser olivo_xylella
olivo <- readxl::read_excel("data/olivo_xylella.xls")
dim(olivo)
olivo %>% # dataset wide (planilla de campo, con 30 columnas de sev por arbol individual)
# le pedimos que apile las columnas conteniendo a las plantas 1 a 30
pivot_longer(`1`:`30`,
# el nombre de las columnas las apile en una columna llamada "tree"
names_to = "tree",
# la observaciones de severidad las apile en una columna llamada sev
values_to = "sev") -> oli_long # el producto de este re-arreglo se llamará "oli_long"
ftable(xtabs(~year+loc+farm, oli_long))Datos canola_maculas
canola <- readxl::read_excel("data/canola_maculas.xlsx")
canola %>%
pivot_longer(inc_15:inc_248,
names_to = "tt",
values_to = "inc",
names_prefix = "inc_")-> can_longCompilemos los 3 datasets formato long en un solo archivo .RData:
(Avanzado) Datos soja_mancha
mancha <- readxl::read_excel("data/soja_mancha.xlsx")
mancha %>%
pivot_wider(names_from = rep, values_from = c(sev, yield)) -> mancha_wide
mancha_wide %>%
pivot_longer(-fungic, names_to = "var", values_to = "val") %>%
separate(var, c('var', 'bk'), sep = '_', convert = TRUE) %>%
spread(var, val, convert = TRUE) %>%
mutate_at(vars(fungic:bk), as.factor) -> mancha_long- Otras funciones interesantes de
tidyr
join